Chapter 2 Web Scraping
The following chapter covers a modern technique with the latest libraries for web scraping in R and related challenges with a focus on the immobiliare.it case. The easiest way of collecting information from websites involves inspecting and manipulating URLs. While browsing web pages urls under the hood compose themselves in the navigation bar according to a certain encoded semantic, specifying domain, url paths and url parameters. As a matter of fact websites can be regarded as a complex system of nested folders where urls are the relative file path to access to the content desired. That implies if a function can mimic the url semantic by providing decoded, human-readable arguments, then any content in the website can be filtered out and later accessed.
Once urls are reproduced through the function they are stored into a variable, then scraping is called on the set of addresses.
The major time improvement with respect to crawlers comes from retrieving a specific set of urls instead of acquiring the entire website sitemap and then searching with keywords.
This is attained by exploiting a scraping workflow library, namely rvest Wickham (2021), which takes inspiration from the scraping gold standard Python library Beautiful Soup (Beautifulsoup?). A search algorithm strategy, calibrated on the specific scraping context, is nested inside scraping functions whose skeleton is reproduced for all the data of interest. The search strategy exploits different CSS selectors that point to different data location within the web page, with the aim to be sure to carry out a comprehensive exploration and to deliver data where available. Functions are then wrapped up around a “main” function that simplifies portability and enables parallelization.
HTTP protocol communication and related main concepts are introduced with the aim to familiarize with internet communication layers focusing on traffic from web server to web clients and viceversa and principal actors involved.
By doing that some opinionated but highly diffused scraping best practices are incorporated into scraping taking inspiration by a further R library Polite (polite?). Revised best practices try to balance scraping efficiency and web etiquette. As a result optimization happens both from the web server side; this is tackled by kindly asking for permission and sending delayed server requests rate based on Robotstxt file requirements. As well as from the web client by preventing scraping discontinuity caused by server blocks thanks to User Agent (HTTP request headers) pool rotation and fail dealers.
Parallel computing is carried out due to data fast obsolescence, since the market on which scraping functions are called is vivid and responsive. At first concepts and are introduced and then main centered on the specific R parallel ecosystem. Then a run time scraping benchmark is presented for two different modern parallel back end options future Bengtsson (2020a) and doParallel (doParallel?), along with two parallel looping paradigma, furrr Vaughan and Dancho (2020) and foreach (foreach?). Both of the two combinations have showed similar results, nevertheless the former offers a more {Tidiverse} coherence and a more comfortable debugging experience.
Furthermore an overview of the still unlocked challenges is provided on the open source project and possible improvements, with the sincere hope that the effort put might be extended or integrated. In the end a heuristic overview on the main legal aspect is offered bringing also an orientation inspired by a “fair balance” trade off between web scraping practices and the most common claims. Then a court case study about a well known scraping litigation is brought demonstrating how law is not solid in this area and how scraping market should find its own equilibrium.
2.1 A Gentle Introduction on Web Scraping
The World Wide Web (WWW or just the web") data accessible today is calculated in zettabytes (Cisco 2020) (\(1\) zettabyte = \(10^{21}\) bytes). This huge volume of data provides a wealth of resources for researchers and practitioners to obtain new insights in real time regarding individuals, organizations, or even macro-level socio-technical phenomena (Krotov and Tennyson 2018). Unsurprisingly, researchers of Information Systems are increasingly turning to the internet for data that can address their research questions (2018). Taking advantage of the immense web data also requires a programmatic approach and a strong foundation in different web technologies. Besides the large amount of web access and data to be analyzed, there are three rather common problems related to big web data: variety, velocity, and veracity (Krotov and Silva 2018), each of which exposes a singular aspect of scraping and constitutes some of the challenges fronted in later chapters. Variety mainly accounts the most commonly used mark-up languages on the web used for content creation and organization such as such as HTML (“HTML” 2020), CSS (“CSS” 2020), XML (contributors 2020j) and JSON (contributors 2020g). Sometimes Javascript (contributors 2020f) components are also embedded into websites. In this cases dedicated parsers are required which would add a further stumbling block. Starting from these points scraping requires at least to know the ropes of these technologies which are also assumed in this analysis. Indeed later a section will be partially dedicated to familiarize with the inner internet mechanism that manages the exhanges of information, such as HTTP protocols. Velocity: web data are in continuous flow status: it is created in real time, modified and changed continuously. This massively impacts the analysis that relies on those data which, as times passes, becomes obsolete. However it also suggests the speed and pace at which data should be collected. From one hand data should be gathered as quicker as possible so that analysis or softwares are up-to-date, section 2.7. From the other this should happen in any case by constraining speed to common shared scraping best practices, which require occasional rests in requesting information. The latter issue is faced later in section 2.4. Veracity: Internet data quality and usability are still surrounded by confusion. A researcher can never entirely be sure if the data he wants are available on the internet and if the data are sufficiently accurate to be used in analysis. While for the former point data can be, from a theoretical perspective, accurately selected it can not be by any means predicted to exist. This is a crucial aspects of scraping, it should take care of dealing with the possibility to fail, in other words to be lost. The latter point that points to data quality is also crucial and it is assessed by a thoughtful market analysis that mostly assures the importance of immobiliare.it as a top player in italian real estate. As a consequence data coming from reliable source is also assumed to be reliable. Furthermore web scraping can be mainly applied in two common forms as in (Dogucu and Cetinkaya 2020): the first is browser scraping, where extractions takes place through HTML/XML parser with regular expression matching from the website’s source code. The second uses programming interfaces for applications, usually referred to APIs. The main goal of this chapter is to combine the two by shaping a HTML parser and make the code portable into an RESTful API whose software structure is found at ??. Regardless of how difficult it is the process of scraping, the circle introduced in “Scraping the Web” (2014) and here revised with respect to the end goal, is almost always the same. Most scraping activities include the following sequence of tasks:
- Identification of data
- Algorithm search Strategy
- Data collection
- Data preprocess
- Data conversion
- Debugging and maintenance
- Portability
Scraping essentially is a clever combination and iteration of the previous tasks which should be heavily shaped on the target website or websites.
2.2 Anatomy of a url and reverse engineering
Uniform Resource Locators (URLs) (contributors 2020h), also known as web addresses, determine the location of websites and other web contents and mechanism to retrieve it. Each URL begins with a scheme, purple in figure 2.2, specifying the protocol used to communicate client-application-server contact i.e. HTTPS. Other schemes, such as ftp (File transmission protocol) or mailto for email addresses correspond to SMTP (Simple Mail Transfer Protocol) standards.
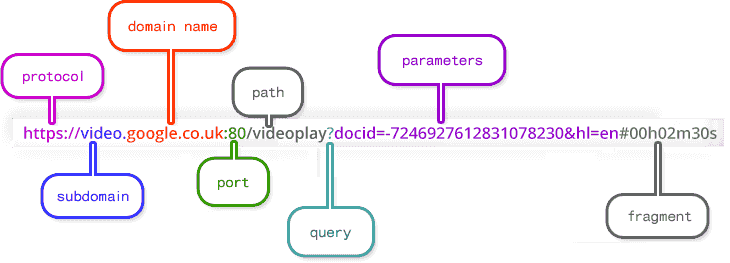
The domain name in red in figure 2.2, with a specific ID, indicates the server name where the interest resource is stored. The domain name is sometimes accompanied with the port whose main role is to point to the open door where data transportation happens. Default port for Transmission Control Protocol ( TCP ) is 80. In the following chapter ports will play a crucial role since a compose file wiill instruct containers (3.2) to open and route communication through these channels and then converge the whole traffic into a secured one 3.3.
Typically domain name are designed to be human friendly, indeed any domain name has its own proprietary IP and public IP (IPv4 and IPv6) address which is a complex number, e.g. local machine IP is 95.235.246.91. Here intervenes DNS whose function is to redirect domain name to IP and vice versa. The path specifies where the requested resource is located on the server and typically refers to a file or directory. Moving towards folders requires name path locations separated by slashes. In certain scenarios, URLs provide additional path information that allows the server to correctly process the request. The URL of a dynamic page (those of who are generated from a data base or user-generated web content) sometimes shows a query with one or more parameters followed by a question mark. Parameters follow a “field=value” scheme each of which is separated by a “&” character for every different parameter field, 6th character from the end in figure 2.2 parameter space. Each further parameter field added is appended at the end of the url string enabling complex and specific search queries.
Fragments are an internal page reference often referred to as an anchor. They are typically at the end of a URL, starting with a hash (#) and pointing to specific part of a HTML document. Note that this is a full browser client-side operation and fragments are used to display only certain parts of already rendered website.
The easiest way of collecting information from websites often involves inspecting and manipulating URLs which refer to the content requested. Therefore urls are the starting point for any scraper and they are also the only functional argument to be feeding to. Url parameters indeed help to route web clients to the requested information and this is done under the hood and unconsciously while the user is randomly browsing the web page.
Let us assume to express the necessity to scrape only certain information from a generic website.
Then if this data to be scraped can be circumscribed by properly setting url parameters, under those circumstances it is also demanded a way to consciously compose these urls. In other words a function (or a sevice) needs to mould urls by mimicking their mutations operated by browser while the user is navigating. As a matter of fact as filters (i.e. parameters) are applied to the initial search page for immobiliare.it then parameters populate the navigation bar. For each of the filters specified a new parameter field and its own selected value are appended to the url string according to the website specific semantic. Each website has its own sematic.
As an example are applied directly to the domain name https://www.immobiliare.it/ the following filters (this is completely done in the dedicated panel):
- rental market (the alternative is selling)
- city is Milan
- bathrooms must be 2
- constrained zones search on “Cenisio” and “Fiera”
The resulting url is:
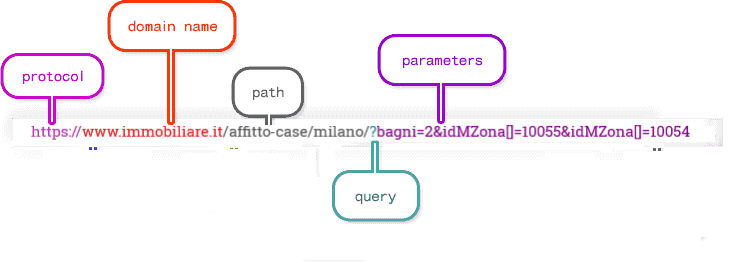
Figure 2.2: immobiliare url composed according to some filters, author’s source
At first glance immobiliare.it does not enact a clean url (contributors 2020a) structure, which ultimately would simplify a lot the reverse sematic process.
In truth parameters follows a chaotic semantic. While the filter city=“milano” is located in the url path the remaining are transferred to the url parameters. For some of them the logical trace back from the parameter field-value to their exact meaning is neat, i.e. bagni=2 and can be said clean. Unfortunately for the others the sematinc is not obvious and requires a further reverse layer to deal with.
In addition to this fact the url in figure 2.2 readdress to the very first page of the search meeting the filter requirements, which groups the first 25 rental advertisements. The following set of 25 items can be reached by relocating the url address to:
https://www.immobiliare.it/affitto-case/milano/?bagni=2&idMZona[]=10055&idMZona[]=10054&pag=2. The alteration regards the last part of the url and constitutes a further url parameter field to look for. Note that the first url does not contain “&pag=1.” For each page browsed by the user the resulting url happen to be the same plus the prefix “&pag=” glued with the correspondent \(n\) page number (from now on referred as pagination). This is carried on until pagination reaches either a stopping criteria argument or the last browsable web page (pagination sets as default option 10 pages, which returns a total of 250 rental advertisement).
Therefore for each reversed semantic url are obtainable 25 different links, see figure 2.3 that is where actually are disclosed relevant data and the object of scraping. Links belonging to the 25 items set share the same anatomy: https://www.immobiliare.it/annunci/84172630/ where the last path is associated to a unique
ID, characteristic of the rental property. Unfortunately there is not any available solution to retrieve all the existing ID, therefore links needs to collected directly from “main” url in figure 2.2 as an obvious choice.
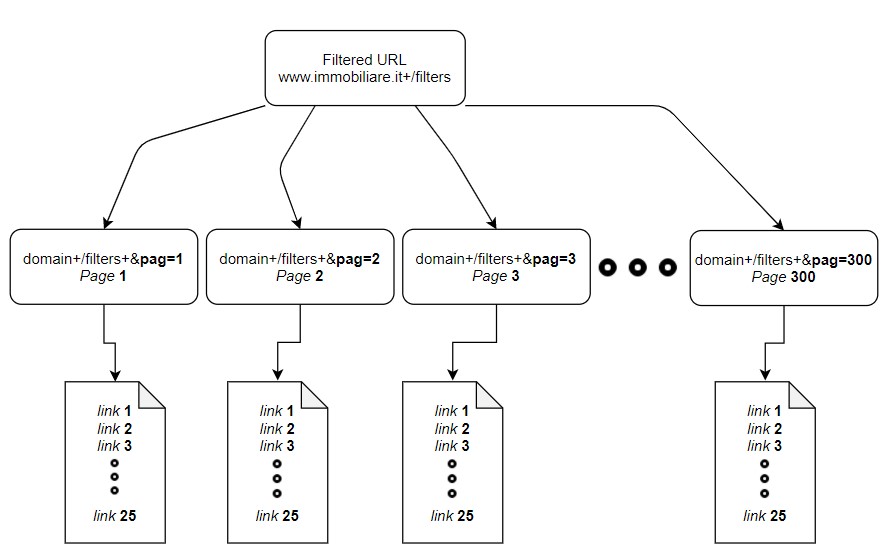
Figure 2.3: immobiliare.it website structure, author’s source
Therefore 4 steps are required to reverse engineer the url (2014) and to ultimately make the links access available:
- Determine how the URL syntactic works for each parameter field
- Build the url based on the reverse engineered sematic:
- those ones who need an ID parameter value
- clean ones who need to only explicit the parameter value
- Pagination is applied to the url until stopping criteria are met
- Obtain the links for each urls previously generated
Once identified the inner composition mechanism by an insistent trial and error then the url restoration could starts. Parameter values for those that requires an ID in figure 2.2 are encoded is a way that each number is associated to its respective zone ID e.g. as in figure 2.2 “Fiera” to 10055 or “Cenisio” to 10054. Therefore a decoding function should map the parameter value number back to the correspondent human understandable name e.g from 10055 to “Fiera” or 10054 to “Cenisio,” the exactly opposite logical operation. The decoding function exploits a JSON database file that matches for each ID its respective zone name exploiting suitable JSON properties. The JSON file is previously compounded by generating a number of random url queries and subsequently assigning the query names to their respective ID. As soon as the JSON file is populated the function can take advantage of that database and compose freely urls at need. Pagination generates a set of urls based on the number of pages requested. In the end for each urls belonging to the set of urls, links are collected by a dedicated function and stored into a vector. Furthermore if the user necessitate to directly supply a precomposed url the algorithm overrides the previous object and applies pagination on the provided url. The pseudocode in figure 2.4 paints the logic behid the reverse egineering process.

Figure 2.4: pseudo code algorithm to reverse engineer url, author’s source
2.2.1 Scraping with rvest
Reverse engineered urls are then feeded to the scraper which arranges the process of scraping according to the flow chart imposed by rvest in figure 2.5. The sequential path followed is highlighted by the light blue wavy line and offers one solution among all the alternative ways to get to the final content. The left part with respect to the central dashed line of figure 2.5 takes care of setting up the session and parsing the response. As a consequence at first scraping in consistent way requires to open a session class object with html_session. Session arguments demands both the target url, as built in 2.4 and the request headers that the user may need to send to the web server. Data attached to the web server request will be further explored later in section2.5.1, tough they are mainly 4: User Agents, emails references, additional info and proxy servers. The session class objects contains a number of useful data regarding either the user log info and the target website such as: the url, the response, cookies, session times etc. Once the connection is established (response 200), functions that come after the opening rely on the object and its response. In other words while the session is happening the user will be authorized with the already provided headers data. As a result jumps from a link to the following within the same session are registered by in the object. Most importantly sessions contain the xml/html content response of the webpage, that is where data needs to be accessed.
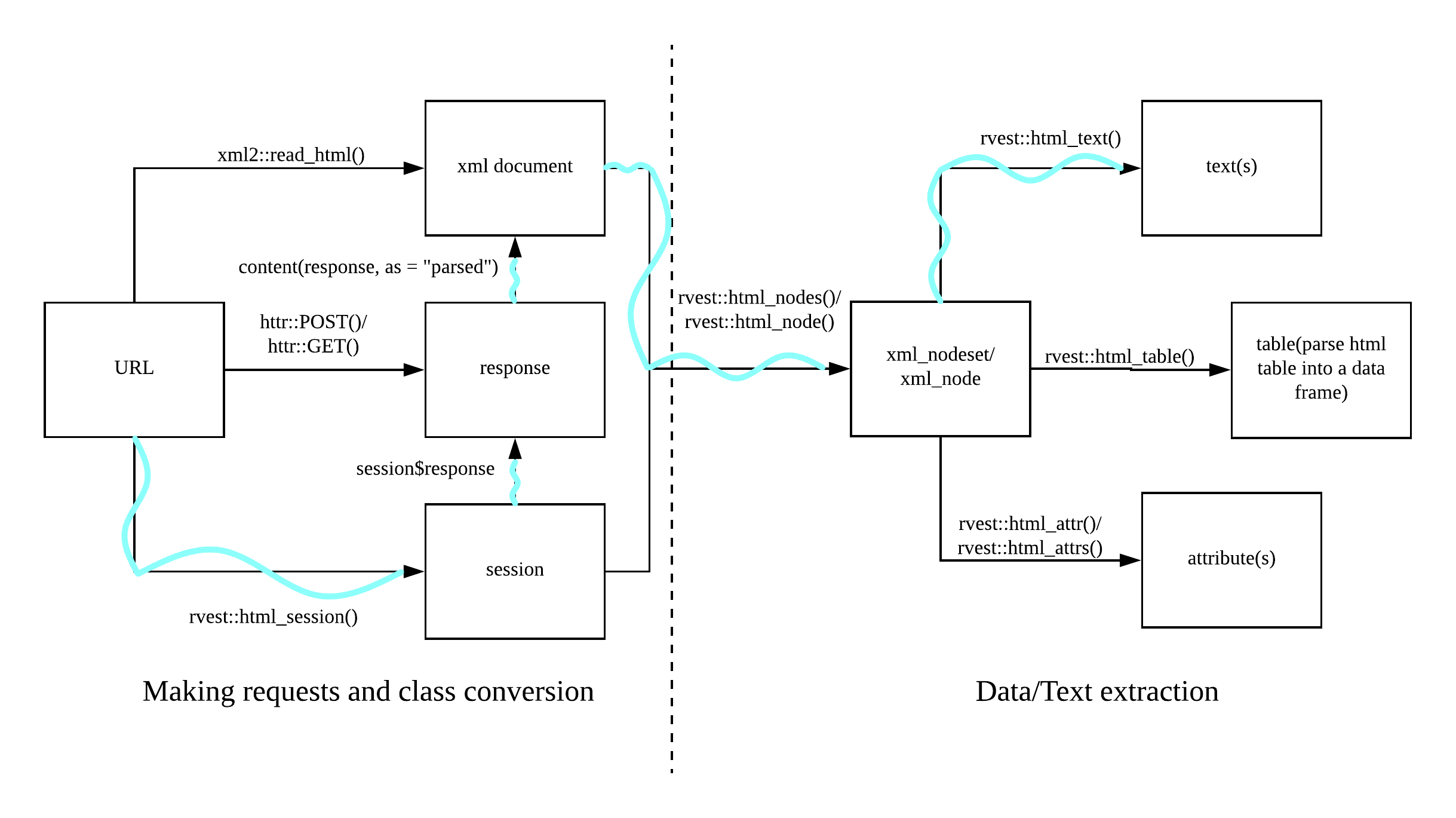
Figure 2.5: rvest general flow chart, author’s source
Indeed at the right of dashed line in 2.5 are represented the last two steps configured into two rvest(Wickham 2021) functions that locate the data within the HTML nodes and convert it into a human readble text, i.e. from HTML/XML to text. The most of the times can be crafty to find the exact HTML node or nodes set that contains the data wanted, expecially when HTML trees are deep nested and dense. html_node function provides and argument that grants to specify a simple CSS/XPATH selector which may group a set of HTML/XML nodes or a single node. Help comes from an open source library and browser extension technology named SelectorGadget. SelectorGadget (Cantino and Maxwell 2013) which is a JavaScript bookmark that allows to interactively explore which CSS selector is needed to gather desired components from a webpage. Data can be repeated many times into webpages so the same information can be found at multiple CSS queries. This fact highlights one of the priciples embodied in the follwing section 2.3 accroding to which searching methods gravitates. Once the CSS query points address to the desired content then data finally needs to be converted into text. This is what explicitly achieve html_text.
2.3 Searching Technique for Scraping
The present algorithm in figure 2.7 imposes a nested sequential search strategy and gravitates around the fact that data within the same webpage is repeated many times, so there exist multiple CSS selections for the exact same information. Furthermore since data is repeated has also less probability to be missed. CSS sequential searches are calibrated from the highest probability of appearance in that CSS selector location to the lowest so that most visited locations are also the the most likely to grab data.
A session object opensess, the one seen in 2.5), is initialized sending urls built in 2.4. The object opensess constitutes a check point obj because it is reused more than once along the algorithm flow. The object contains session data as well as HTML/XML content. Immediately after another object price parses the sessions and points to a CSS query through a set of HTML nodes. The CSS location .im-mainFeatures__title addresses a precise group of data which are found right below the main title. Expectations are that monthly price amount in that location is a single character vector string, containing price along with unnecessary non-UTF characters. Then the algorithm bumps into the first if statement. The logical condition checks whether the object price first CSS search went lost. If it does not the algorithm directly jumps to the end of the algorithm and returns a preprocessed single quantity. Indeed if it does it considers again the check point opensess and hits with a second css query .im-features__value , .im-features__title, pointing to a second data location. Note that the whole search is done within the same session (i.e. reusing the same session object), so no more additional request headers 2.5.1 has to be sent). Since the second CSS query points to data sequentially stored into a list object, the newly initialized price2 is a type list object containing various information. Then the algorithm flows through a second if statement that checks whether "prezzo" is matched in the list, if it does the algorithm returns the +1 position index element with respect to the “prezzo” position. This happens because data in the list are stored by couples sequentially (as a flattened list), e.g. list(title, “Appartamento Sempione,” energy class, “G,” “prezzo,” 1200/al mese). Then in the end a third CSS query is called and a further nested if statement checks the emptiness of the latest CSS query. price3 points to a hidden JSON object within the HTML content. If even the last search is lost then the algorithm escapes in the else statement by setting NA_Character_, ending with any CSS query is able to find price data.
The search skeleton used for price scraping constitutes a standard reusable search method in the analysis for all the scraping functions. However for some of the information not all the CSS location points are available and the algorithm is forced to be rooted to only certain paths, e.g. “condizionatore” can not be found under main title and so on.

Figure 2.7: pseudo code algorithm for price search, author’s source
Once all the functions have been designed and optimized with respect to their scraping target they need to be grouped into a single “main” fastscrape function, figure 2.8. This is accomplished into the API function endpoint addressed in section 3.1.1, which also applies some sanitization, next chapter section 3.1.2, on users inputs and administers also some security API measures, as in 3.1.3 outside the main function. Moreover as it will be clear in section 2.7 the parallel back end will be registered outside the scraping function for unexplained inner functioning reasons.

Figure 2.8: pseudo code algorithm structure for fatstscrape, author’s source
pseudo code
2.4 Scraping Best Practices and Security provisions
Web scraping have to naturally interact multiple times with both the client and server side and as a result many precautions must be seriously taken into consideration. From the server side a scraper can forward as many requests as it could (in the form of sessions opened) which might cause a traffic bottleneck (DOS attack contributors (2020b)) impacting the overall server capacity. As a further side effect it can confuse the nature of traffic due to fake user agents 2.5.1 and proxy servers, consequently analytics reports might be driven off track. Those are a small portion of the reasons why most of the servers have their dedicated Robots.txt files. Robots.txt Meissner (2020) are a way to kindly ask webbots, spiders, crawlers to access or not access certain parts of a webpage. The de facto “standard” never made it beyond a informal “Network Working Group internet draft.” Nonetheless, the use of robots.txt files is widespread due to the vast number of web crawlers (e.g. Wikipedia robot, Google robot). Bots from the own Google, Yahoo adhere to the rules defined in robots.txt files, although their interpretation might differ.
Robots.txt files (Meissner and Ren 2020) essentially are plain text and always found at the root of a website’s domain. The syntax of the files follows a field-name value scheme with optional preceding user-agent. Blocks are separated by blank lines and the omission of a user-agent field (which directly corresponds to the HTTP user-agent field, cleared later in 2.5.1) is seen as referring to all bots. The whole set of possible field names are pinpointed in Google (2020), some important are: user-agent, disallow, allow, crawl-delay, sitemap and host. Some common standard interpretations are:
- Finding no robots.txt file at the server (e.g. HTTP status code 404) implies full permission.
- Sub-domains should have their own robots.txt file, if not it is assumed full permission.
- Redirects from subdomain www to the domain is considered no domain change - so whatever is found at the end of the redirect is considered to be the robots.txt file for the subdomain originally requested.
A comprehensive scraping library that observes a web etiquette is the polite (polite?) package. Polite combines the effects of robotstxt, ratelimitr (ratelimitr?) to limit sequential session requests together with the memoise (Wickham et al. 2017) for robotstxt response caching. Even though the solution meets the politeness requirements (from server and client side) ratelimitr is not designed to run in parallel as documented in the vignette (ratelimitr?). This is a strong limitation as a result the library is not applied. However the 3 simple but effective web etiquette principles around, which is the package wrapped up, describe what are the guidelines for a “polite” session:
The three pillars of a polite session are seeking permission, taking slowly and never asking twice.
The three pillars constituting the Ethical web scraping manifesto (Densmore 2019) are considered as common shared best practices that are aimed to self regularize scrapers. In any case these guidelines have to be intended as eventual practices and by no means as required by the law. However many scrapers themselves, as website administrators or analyst, have been fighting for many and almost certainly coming years with bots, spiders and derivatives. As a matter of fact intensive scraping might fake out real client navigation logs and confuse digital footprint, which results in induced distorted analytics. On the other hand if data is not given and APIs are not available, then scraping is sadly no more an option.
Therefore throughout this analysis the goal will be trying to find a well balanced trade-off between interests on the main actors involved.
Newly balanced (with respect to the author thought) guidelines would try to implement at first an obedient check on the validity of the path to be scraped through a cached function. Secondly it will try to limit request rates to a more feasible time delay, by keeping into the equation also the client time constraints. In addition it should also guarantee the continuity in time of scraping not only from the possibility to fail section (possibly)), but also from servers “unfair” denial (in section 2.5.1).
With that said a custom function caches the results of robotstxt into a variable i.e. polite_permission. Then paths allowed are evaluated prior any scraping function execution. Results should either negate or affirm the contingency to scrape the following url address.
#> Memoised Function:
#> [1] TRUEpolite_permission is then reused to check, if any, the server suggestion on crawl relay. In this particular context no delays are kindly advised. As a default polite selection delay request rates are set equal to 2.5 seconds. Delayed are managed through the purrr stack. At first a rate object is initialized based on polite_permission results, as a consequence a rate_sleep delay is defined and iterated together with any request sent, as in (rate_delay?).
get_delay = function(memoised_robot, domain) {
message(glue("Refreshing robots.txt data for %s... {domain}"))
temp = memoised_robot$crawl_delay
if (length(temp) > 0 && !is.na(temp[1,]$value)) {
star = dplyr::filter(temp, useragent=="*")
if (nrow(star) == 0) star = temp[1,]
as.numeric(star$value[1])
} else {
2.5L
}
}
get_delay(rbtxt_memoised, domain = dom)
#> [1] 2.52.5 HTTP overview
URLs in browsers as in 2.1 are a way to access to web content whether this accounts for getting from one location to the following, or checking mails, listening to musics or downloading files. However Internet communication is a stratification of layers conceived to make the whole complex system working. In this context URLs are the layer responsible for user interaction. The rest of the layers which involve techniques, standards and protocols, are called in ensemble Internet Protocols Suite ( IPS ) (2014). The TCP (Transmission Control Protocol) and IP (Internet Protocol) are two of the most important actors on the IP Suite and their role is to represent the Internet layer (IP) and the transportation layer (TCP). In addition they also guarantee trusted transmission of data. Inner properties and mechanism are beyond the scope of the analysis, luckily they are not required in this context. Resting on the transportation layer there are specialized message exchange protocols such as the HTTP (Hyper Text Transfer Protocol), FTP (File Transfer Protocol). In addition, there may be also e-mail exchange protocols for transmission, such as Post Office Protocol (POP) for Email Recovery and for storage and retrieval, IMAP (Internet Message Acccess Protocol). The aforementioned protocols describe default vocabulary and procedures to address particular tasks for both clients and servers and they can be ascribed to the transportation layer. HTTP is the most widespread, versatile enough to ask for almost any resource from a server and can also be used to transfer data to the server rather than to recover. In figure 2.9 is painted a schematized version of a User-Server general HTTP communication/session. If a website e.g. immobiliare.it is browsed from a web browser e.g. Chrome (the HTTP client) then the client is interrogating a Domain Name System (DNS) which IP address is associated with the domain part of the URL. When the browser has obtained the IP address as response from the DNS server then connection/session is established with HTTP server via TCP/IP. From a content perspective data is gathered piece-by-piece, if the content is not exclusively HTML then the the browser client renders the content as soon as it receives data.
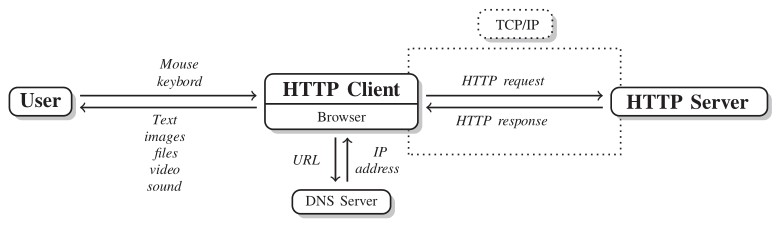
Figure 2.9: User-Server communication scheme via HTTP, source “Scraping the Web” (2014)
Furthermore HTTP should be borne in mind two essential facts.
- HTTP is not only a hypertext protocol, but it is used for all sorts of services (i.e. APIs)
- HTTP is a stateless protocol, which means that response and request and the the resulting interaction between client and server is managed by default as it were the first time they connected.
HTTP messages consist of three sections – start line, headers and body – whether client requests or server response messages. The start line of the server response begins with a declaration on the highest HTTP version. The header underneath the start line contains client and server meta data on the preferences for content displaying. Headers are arranged in a collection of name-value pairs. The body of an HTTP message contains the content of the response and can be either binary or plain text. Predominantly in the context of the analysis are headers which are the fields where lay the definition of the actions to take upon receiving a request or response. For what concerns the analysis the focus is on identification headers (both in request and response) whose role is to describe user preferences when sessions are opened i.e. default language, optimization of content display throughout devices. The exploited ones are:
(metti anche altra roba da altre fonti)
- Authorization (request): authentication field allows to insert personal credentials to access to dedicated content (log in to the immobiliare.it account). Credentials in requests are not really encrypted, rather they are encoded with Base64. Therefore they can be easily exposed to security breaches, which it does not happen when using HTTP (HTTP Security) that applies encryption to basic authentication, extensively presented in 3.5.
- Set-Cookie (response): Cookies allow the server to keep user identity. They are a method to transform stateless HTTP communication (second point in previous ) into a secure discussion in which potential answers rely on past talks.
- User-Agent (request), faced in next section 2.5.1.
2.5.1 User Agent and further Identification Headers Spoofing
In the HTTP identification headers the UA string is often considered as content negotiator (contributors 2020i). One the basis of the UA, the web server can negotiate different CSS loadings, custom JavaScript delivery or it can automatically translate content on UA language preferences (WhoIsHostingThis.com 2020). UA is a dense content string that includes many User details: the user application or software, the operating system (and versions), the web client, the web client’s version, as well as the web engine responsible for content displaying (e.g. AppleWebKit). When the request is sent from an application software as R (no web browser), the default UA is set as:
#> [1] "libcurl/7.64.1 r-curl/4.3 httr/1.4.2"Indeed when a request comes from a web browser a full UA example and further components breakdown is (current machine):
Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36
- The browser application is Mozilla build version 5.0 (i.e. ‘Mozilla-compatible’).
- The Operating System is Windows NT 6.3; WOW64, running on Windows.
- The Web Kit provides a set of core classes to display web content in windows (UserAgentString.com 1999), build version 537.36.
- The Web Browser is Chrome version 45.0.2454.85.
- The client is based on Safari, build 537.36.
The UA string is also one of the main responsible according to which Web crawlers and scrapers through a dedicated name field in robotstxt 2.4 may be ousted from accessing certain parts of a website. Since many requests are sent the web server may encounter insistently the same UA (since the device from which they are sent is the same) and as consequence it may block requests associated to the own UA. In order to avoid server block the scraping technique adopted in this analysis rotates a pool of UAs. That means each time requests are sent a different set of headers are drawn from the pool and then combined. The more the pool is populated the larger are the UA combinations. The solution proposed tries in addition to automatically and periodically resample the pool as soon as the website from which U agents ID are extracted updates newer UA strings.
set.seed(27)
url = "https://user-agents.net/"
agents = read_html(url) %>%
html_nodes(css = ".agents_list li") %>%
html_text()
agents[sample(1)]
#> [1] "Mozilla/5.0 (Linux; Android 11; CPH2065 Build/RP1A.200720.011; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/87.0.4280.141 Mobile Safari/537.36 [FB_IAB/FB4A;FBAV/305.1.0.40.120;]"The same procedure has been applied to the From identification header attached to the request. E-mails, that are randomly generated from a website, are scraped and subsequently stored into a variable. A further way to imagine what this is considering low level API calls to dedicated servers nested into a more general higher level API. However UA field name technology has been recently sentenced as superseded in favor of a newer (2020) proactive content negotiator named Hints contributors (2020e).
An even more secure approach may be accomplished rotating proxy servers between the back and forth sending-receiving process.While the user is exploiting a proxy server, internet traffic in the form of HTTP request, figure 2.11 flows through the proxy server on its way to the HTTP server requested. The request then comes back through that same proxy server and then the proxy server forwards the data received from the website back to the client. Form a user perspective benefits regards:
- anonymity on the Web
- overcome restriction access to IPs imposed to requests coming from certain locations
Many proxy servers are offered as paid version. In this particular case security barrijers are not that high and this suggests to not apply them. As a further disclaimer many online services are providing free proxies server access, but this comes at a personal security cost due to a couple of reasons:

Figure 2.11: proxy middle man,, source “Scraping the Web” (2014)
- Free plan Proxies are shared among a number of different clients, so as long as someone has used them in the past for illegal purposes the client is indirectly inheriting their legal infringements.
- Very cheap proxies, for sure all of the ones free, have the activity redirected on their servers monitored, profiling in some cases a user privacy violation issue.
2.6 Dealing with failure
During scraping many difficulties coming from different source of problems are met. Some of them may come from the website’s layout changes (2.3), some of them may regard internet connection, some other may have been caused by security breaches (section 2.5.1).
One of the most inefficient event it can happen is an unexpected error thrown while sending requests that causes all the data acquired and future coming going lost. In this particular context is even more worrying since scraping “main” functions is able to call 34 different functions each of which points to a different data location. Within a single function invocation, pagination contributes to initialize 10 pages. Each single page includes 25 different single links leading to a number of 8500 single data pieces. Unfortunately the probability given 8500 associated to one piece being lost, unparsed is frankly high.
For all the reasons said scraping functions needs to deal with the possibility to fail. This is carried out by the implementation of purrr vectorization function map (and its derivatives) and the adverb possibly (possibly?). Possibly takes as argument a function (map iteration over a list) and returns a modified version. In this case, the modified function returns an empty dataframe regardless of the error thrown. The approach is strongly encouraged when functions need to be mapped over large objects and time consuming processes as outlined in Hadley Wickham (2017) section 21.6. Moreover vectorization is not only applied to a vector of urls, but also to a set of functions defined in the environemnt.

Figure 2.12: pseudo code for a generic set of functions applied with possibly fail dealers , author’s source
2.7 Parallel Scraping
Scraping run time is crucial when dealing with dynamic web pages. This assumption is stronger in Real Estate rental markets where time to market is a massive competitive advantage. From a run time perspective the dimension of the problem requires as many html session opened as single links crawled (refer to previous section 2.6). As a result computation needs to be parallelized in order to be feasible. The extraordinary amount of time taken in a non-parallel environment is caused by R executing scraping on a single processor sequentially url-by-url in a queue, left part of figure 2.13 (i.e. single threaded computing).
This requires multiple execution units and modern processors architecture provide multiple cores on a single processor and a way to redistribute computation (i.e. multi threaded computing). As a result tasks can be split into smaller chunks over processors and then multiple cores for each processor, right part of figure 2.13. Therefore Parallel scraping (sometimes improperly called asynchronous) functions are proposed, so that computation do not employ vast cpu time (i.e. cpu-bound) and space.
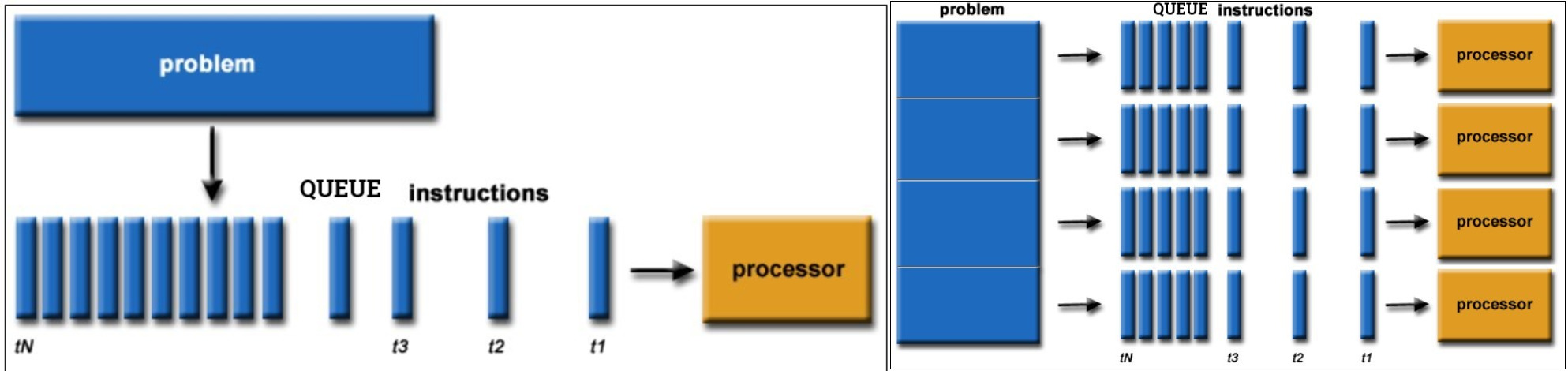
Parallel execution heavily depends on hardware and software choice. Linux environments offers multi-core computation through forking (contributors 2020c) (only on Linux) so that global variables are directly inherited by child processes. As a matter of fact when computation are split over cores they need to import whatever it takes to be carried out, such as libraries, variables, functions. From a certain angle they need to be treated as a containerized stand-alone environments. This can not happen in Windows (local machine) since it does not support multicore.
future::supportsMulticore()
#> [1] FALSECluster processing is an alternative to multi-core processing, where parallelization takes place through a collection of separate processes running in the background. The parent R session instructs the dependencies that needs to be sent to the children sessions.
This is done by registering the parallel back end. Arguments to be supplied mainly regards the strategy (i.e. multi-core cluster, also said multisession) and the working group. The working group is a software concept (“What Is Parallel Computing” 2020), that points out the number of processes and their relative computing power/memory allocation according to which the task is going to be split. Moreover from a strictly theoretic perspective the workers (i.e. working group single units) can be greater than the number of physical cores detected. Although parallel libraries as a default choice (and choice for this analysis) initializes as many workers as physical HT (i.e. Hyper Threaded) cores.
Parallel looping constructor libraries generally pops up as a direct cause of new parallel packages. The latest research activity by Bengtsson (doFuture?) indeed tries to unify all the previous back ends under the same umbrella of doFuture. The latter library allows to register many back ends for the most popular parallel looping options solving both the dependency inheritance problem and the OS agnostic challenge.
The two alternatives proposed for going parallel are Future Bengtsson (2020a) with furrr Vaughan and Dancho (2020) and doFuture (doFuture?) along with the foreach (foreach?) loop constructor. The former is a generic, low-level API for parallel processing as in Bengtsson (2020b). The latter takes inspiration by the previous work and it provides a back-end agnostic version of doParallel (doParallel?). Further concepts on parallel computing are beyond the scope of the analysis, some valuable references are Barney (2020) and “What Is Parallel Computing” (2020).
2.7.1 Parallel furrr+future
Simulations are conducted on a not-rate-delayed (section 2.4) and restricted set of functions which may be considered as a “lightweight” version of the final API scraping endpoint. As a disclaimer run time simulations may not be really representative to the problem since they are performed on a windows 10, Intel(R) Core(TM) i7-8750H 12 cores RAM 16.0 GB local machine. Indeed the API is served on a Linux Ubuntu distro t3.micro 2 cores RAM 1.0 GB server which may adopt forking. Simulations for the reasons said can only offer a run time performance approximation for both of the parallel + looping constructor combinations.
The first simulation considers furrr which enables mapping (i.e. vectorization with map) through a list of urls with purrr and parallelization with Future. Future gravitates around a programming concept called “future,” initially introduced in late 70’s by Baker (Baker and Hewitt 1977). Futures are abstractions for values that may be available at a certain time point later (2020a).
These values are result of an evaluated expression, this allows to actually divide the assignment operation from the proper result computation. Futures have two stages unresolved or resolved. If the value is queried while the future is still unresolved, the current process is blocked until the stage is resolved. The time and the way futures are resolved massively relies on which strategy is used to evaluate them. For instance, a future can be resolved using a sequential strategy, which means it is resolved in the current R session. Other strategies registered with plan(), such as multi-core (on Linux) and multisession, may resolve futures in parallel, as already pointed out, by evaluating expressions on the current machine in forked processes or concurrently on a cluster of R background sessions.
With parallel futures the current/main R process does not get “bottlenecked,” which means it is available for further processing while the futures are being resolved in separate processes running in the background. Therefore with a “multisession” plan are opened as many R background sessions as workers/cores on which chunks of futures (urls) are split and resolved in parallel. From an algorithmic point of view It can be compared to a divide and conquer strategy where the target urls are at first redistributed among workers/cores (unresolved) through background sessions and then are scraped in equally distributed chunks (resolved).
Furthermore furrr has also a convenient tuning option which can interfere with the redistribution scheduling of urls’ chunks over workers. The argument scheduling can adjust the average number of chunks per worker. Setting it equal to 2 brings dinamicity (2020) to the scheduling so that if at some point a worker is busier then chunks are sent to the more free ones.
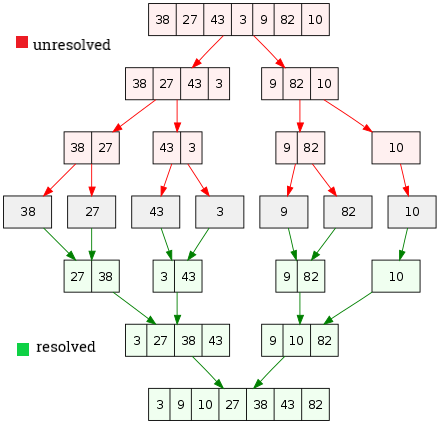
Figure 2.14: Futures envisaged as Divide & Conquer algorithm, author’s source
The upper plot in figure 2.15 are 20 simulations of 100 url (2500 data points) performed by the lightweight scraping. On the horizontal axis are plotted the 20 simulations and on the vertical axis are represented the respective elapsed times. One major point to breakdown is the first simulation run time measurement which is considerably higher with respect to the others i.e. 15 sec vs mean 7.72 sec. Empirical demonstrations traces this behavior back to the opening time for all the background sessions. As a result the more are the back ground sessions/workers, the more it would be the time occupied to pop up all the sessions. As opposite whence many sessions are opened the mean execution time for each simulation is slightly less. The lower plot in in figure 2.15 tries to capture the run time slope behavior of the scraping function when urls (1 to 80) are cumulated one by one. The first iteration scrapes 1 single url, the second iteration 2, the third 3 etc. Three replications of the experiment has been made, evidenced by three colours. The former urls are more time consuming confirming the hypothesis casted before. Variability within the first 40 urls for the three repetitions does not show diversion. However It slightly increases when the 40 threshold is trespassed. Two outliers in the yellow line are visible in the nearby of 50 and 60. One straightforward explanation might be delay in server response. A further point of view may address the workers being overloaded, but no evidences are witnessed on cores activity as in plot 2.16. The measured computational complexity of scraping when \(n\) is number of urls seems to be much more less than linear \(\mathcal{O}(0.06n)\).
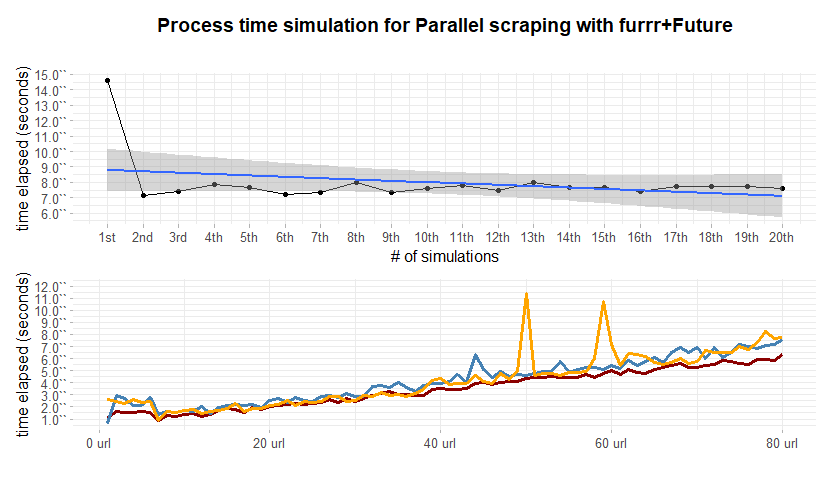
Figure 2.15: computational complexity analysis with Furrr
Figure 2.16: local machine monitoring of cores during parallel scraping
2.7.2 Parallel foreach+doFuture
A second attempt tries to encapsulate foreach (foreach?) originally developed by Microsoft R, being a very fast loop alternative, parallelized with doFuture. The package registered with older back ends required rigorous effort to specify exact dependencies for child process inside foreach arguments .export. From a certain angle the approach could led to an indirect benefit from memory optimization. If global variables needs to be stated than the developer might be forced to focus on limiting packages exporting. Indeed since doFuture implements optimized auto dependency search this problem may be considered solved as in (doFuture?). Two major looping related speed improvements may come from .inorder and .multicombine arguments which both take advantage of parallel split disorder a subsequent recombination of results. In the context where data collection order matters this is extremely wrong, but since in this case order is defined through url composition based on criteria expressed inside nodes contents this can be totally applied. A drawback of enabling .multicombine is a worst debugging experience since errors are thrown at the end when results are reunited and no traceback of the error is given.
The upper part in 2.17 displays lower initialization lag from R sessions opening and parallel execution that also lead to a lower mean execution time of 6.42 seconds. No other interesting behavior are detected. The lower plot displays high similarities with the curves in 2.15 highlighting an outlier in the same proximities of 45/50 urls. The blue simulation repetition shows an uncommon pattern that is not seen in the other plot. Segmented variability from 40 to 80 suggests a higher value which may be addressed do instability. As a result the approach is discarded in favor of furrr + future which also offers both a comfortable {Tidyverse} oriented framework and offers and easy debugging experience.
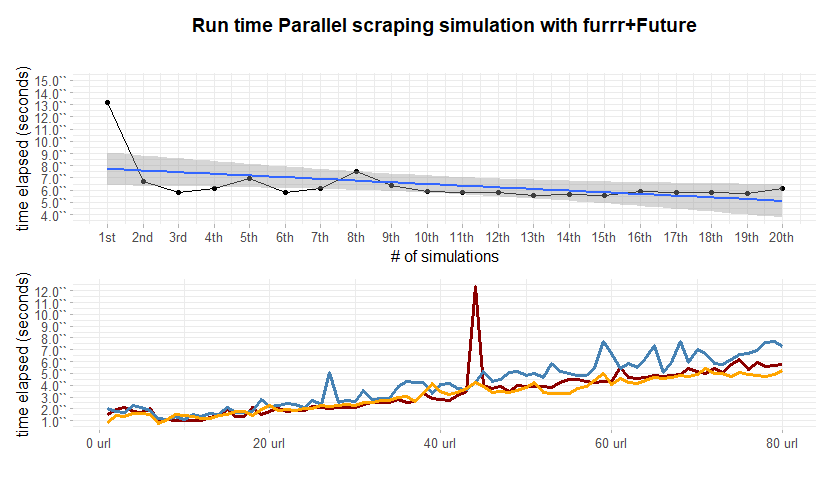
Figure 2.17: computational complexity analysis with Furrr
2.8 Legal Profiles
There is a legitimate gray web scrapers area, not only creating possible new uses for the data collected, but also potentially damaging the host website (Media 2017). Online platforms and the hunger for new data insights are increasingly seeking to defend their information from web scrapers. Online platforms are unfortunately not always successful distinguishing users between polite, impolite and criminals, risking new ones valid competition and creativity. A minimal but effective self limitation can really be satisfactory for both of the parts. In fact courts have fought hard to achieve clear judgments cases for web scraping. The crucial obstacle is a coherent verdicts to ascertain “Kitchen Sink” (Zamora 2019), the standard web claim discontroversy on scraping. Kitchen Sink main arguments are:
- Legal lawsuits under the Computer Fraud and Abuse Act (CFAA) allegation that the defendant “overtook” allowed access (“United States v. Nosal, 676 f.3d 854” 2012)
- Copyright infringement charges under the Digital Millennium Act or federal copyright law Copyright laws (“Authors Guild v. Google, Inc., 804 f.3d 202” 2015)
- “state trespass to chattels claims” (“Register.com, Inc., Plaintiff-Appellee, v. Verio, Inc., Defendant” 2004)
- Contract agreements terms violation claims (2004)
A second challenge to clear verdicts is that there are several purposes for which a business model operates in a continuum of social acceptability hiring web scrapers (Maheedharan 2016). As an example Googlebot ranks, sorts and indexes search results for Google users, without which the search would not optimized and business would not profit from this fact. A more coherent case is represented by the exploitation of scraping on online Real Estate advertiser whose importance is ascertained by the fact that they are the fist house purchase media 52% (USA survey) and searches are expected to be growing by 22% per yeay (Peterson and Merino 2003). On the other hand it is estimated that the 20% of crawlers are actually DoSsing scrapers (LaFrance 2017) causing an economic damage, as in 3.1.3. Unfortunately the majority of web scraping services fall between these two extremes (2017). The most discussed and observed case regards Linkedin Corp. “Linkedin” vs hiQ Labs Inc. (“hiQ”) whose claim argues the exploitation of the former personal profile data to offer a series of HR services. The litigation started by accusing hiQ with “using processes to improperly, and without authorization, access and copy data from LinkedIn’s website” (Corporation 2017). As reinforcement to their arguments they presented also a citation directly form their terms raising the point on copying, web scarping prohibition without their explicit consent. Furthermore Linkedin noted that technical barriers were taken into existence to restrict the access of hiQ to the platform and warned of a breach of state and federal law by ignoring such barriers (2017). As a response Hiq submitted a temporary restricting order to prevent LinkedIn from denying the access to their platform, focusing on the aspect that the motivation was led by an anticompetitive intent. Linkedin’s response brought into the litigation CFAA which actually pollutes argumentation since Court evidences that CFAA is ambiguous whether it is granting or restringing the access to public available website (Edward G. Black 2017). In other words CFAA intent was to protect user data when they are authenticated with passwords, and in no case out of these borders. In the end the litigation moved to the Ninth Circuit where in 2019 it uphelds the preliminary injunction to prohibit LinkedIn from continuing to provide access to publicly accessible LinkedIn member profiles to the claimant hiQ Labs (contributors 2020d).